
Cookie Settings
We use cookies to operate this website, improve usability, personalize your experience and improve our marketing. Your privacy is important to us. Privacy Policy.
April 08, 202415 min read
From theory to practice: The basics of reinforcement learning
Share
Reinforcement learning (RL) is a machine learning approach in which an artificial intelligence agent learns and improves on how to solve tasks through trial and error.
In this article, we will go a bit deeper and discuss:
Fundamentals of reinforcement learning
Different approaches to shaping an AI’s behavior
Balancing AI’s ability to explore and exploit
Future directions and trends
By exploring these areas, you'll gain insights into how reinforcement learning is shaping the future of technology and how it may become one of the most broadly applicable and helpful forms of artificial intelligence. Some of the terms used throughout this article are defined in a previous blog on AI Terminology.
From Theory to Practice: The Basics of Reinforcement Learning
Fundamentals
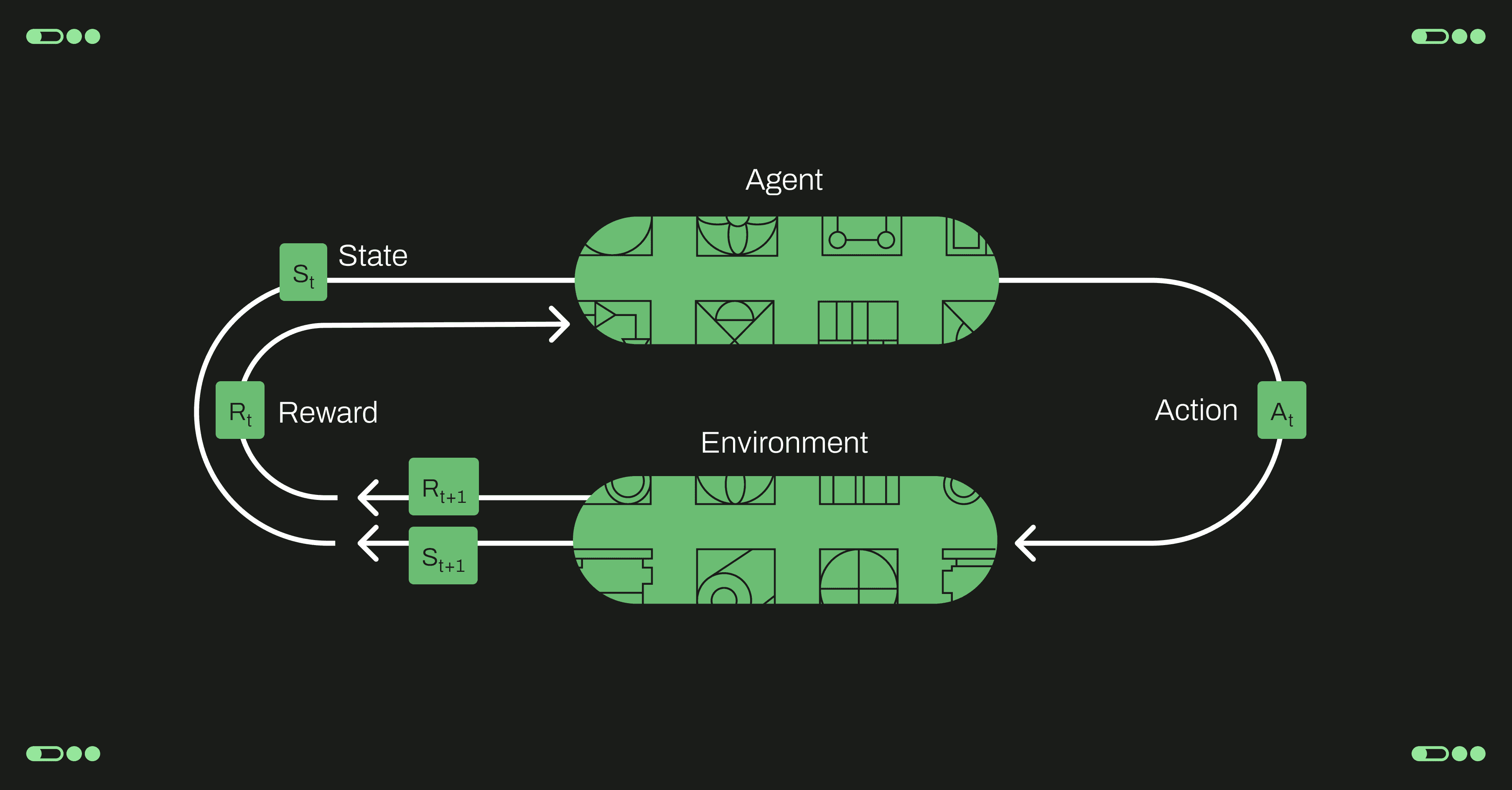
Reinforcement Learning (RL) is an interdisciplinary area of machine learning and optimal control concerned with how an intelligent agent ought to take actions in a dynamic environment in order to maximize a cumulative, long-term reward and not just immediate, short-term rewards.
The main characters of RL are the agent and the environment. The environment is the world that the agent lives in and interacts with. At every step of interaction, the agent can see a full or partial observation of the state of the environment around it. It then decides on an action to take. The environment changes when the agent acts on it, but may also change on its own.
The agent also perceives a reward signal from the environment, a number that tells it how good or bad the current world state is. The goal of the agent is to maximize its cumulative reward, called return. Reinforcement learning methods are ways that the agent can learn behaviors to achieve its goal.
To talk more specifically about what RL does, we need to introduce additional terminology:
Agent. The agent is the decision-maker or the ‘AI’ in RL. It’s the computer program that makes decisions and learns by performing actions within an environment to maximize rewards.
State & Observations. A state is a complete description of the state of the world (environment). There is no information about the world which is hidden from the state. An observation is a partial description of a state, which may omit information. For example, the state of a chiller plant might be represented by its temperature, pressure and flow of the chilled water. When the agent is able to observe the complete state of the environment, we say that the environment is fully observed. When the agent can only see a partial observation, we say that the environment is partially observed.
Action Spaces. Different environments allow different kinds of actions. The set of all valid actions in a given environment is often called the action space. Some environments, like board games, have discrete action spaces, where only a finite number of moves are available to the agent. Other environments, like a robot in a physical world, have continuous action spaces. In continuous spaces, actions are real-valued vectors. This distinction has some quite-profound consequences for methods in deep RL. Some families of algorithms can only be directly applied in one case, and would have to be substantially reworked for the other.
Policy. A policy is a rule used by an agent to decide what actions are possible to take. These could be the rules around moves or a piece of the physical limits of some equipment. They can also refer to constraints like the boundaries of a board game or the min and max temperature span for a mission critical cooling facility. In DeepRL parameterized policies are used. Parameterized Policies are policies whose outputs are computable functions that depend on a set of parameters (e.g. the weights and biases of a neural network) which we can adjust to change the behavior via some optimization algorithm.
Trajectory. A trajectory is a sequence of states and actions in the world. State transitions (what happens to the world between the state at time t, st, and the state at t+1, st+1), are governed by the natural laws of the environment, and depend on only the most recent action, at . Actions come from an agent according to its policy. Trajectories are ways in which the agent may ‘see’ possible state changes in the future based on actions it takes in the immediacy (in accordance with its policy).
Reward & Return. The feedback the agent gets after taking action. It tells the agent if it’s performing well. It also helps the agent learn which actions lead to optimal outcomes. The goal of the agent is to maximize some notion of cumulative reward over a trajectory, but this actually can mean a few things:
- a. finite-horizon undiscounted return, which is just the sum of rewards obtained in a fixed window of steps
- b. infinite-horizon discounted return, which is the sum of all rewards ever obtained by the agent, but discounted by how far off in the future they’re obtained. This formulation of reward includes a discount factor which is a value between 0 and 1.
- a. finite-horizon undiscounted return, which is just the sum of rewards obtained in a fixed window of steps
Value Functions. It’s often useful to know the value of a state, or state-action pair. By value, we mean the expected return if you start in that state or state-action pair, and then act according to a particular policy forever after.
The RL Problem
Whatever the choice of return measure (whether infinite-horizon discounted, or finite-horizon undiscounted), and whatever the choice of policy, the goal in RL is to select a policy which maximizes expected return when the agent acts according to it.
The standard mathematical formalism is given by the Markov Decision Process(MDP). An MDP is a 5-tuple (S, A, R, P, Po), where
S is the set of all valid states
A is the set of all valid actions
R: S * A * S -> R is the reward function, with rt = R(st, at, st+1)
P: S * A -> P(S) is the transition probability function, with P(s’ | s, a) being the probability of transitioning into state s’ if you start in state s and take action a
P0: starting state distribution
The name Markov Decision Process refers to the system obeying the Markov property, i.e. transitions only depend on the most recent state and action, and no prior history.
Approaches in Use
At the heart of RL is programming and it is the complexity of this programming that essentially teaches the agent how to develop “intuition.” The presence of an intuition depends on whether the algorithm has a model-based or model-free approach.
Model-Based vs. Model-Free Approaches
A model-based approach essentially means information that describes the dynamics of the environment is available to the agent. This approach contains some details of the environment that can enhance an agent’s initial predictions about future states and rewards based on previously known actions and their resulting rewards. Like human grandmasters in any game, with so much previous experience they can visualize many possibilities and outcomes before making a move.
In real-world practice, models that capture the dynamics of an environment are often not readily available. However, this can be learned via massive quantities of well-labeled historical data. With this historical data available, the software is able to construct detailed maps to better predict future states and rewards. Their strength lies in anticipation—planning moves and countermoves—in a sophisticated strategy. Their weakness lies in holding on to any bias or paradigm of the dataset - a grandmaster may rely too much on old strategies that work very well but never sees new possibilities that could work better.
Model-free approaches, however, don’t have a model of the environment. Instead, they learn directly from experience, by trying out actions and observing outcomes. Like learning to skateboard. There's no rule book. It’s just you, the board, and the pavement. After many scrapes and landed or missed jumps, you learn what works and what doesn’t. Model-free algorithms thrive on direct experience, adapting through trial and error without preconceived notions of the environment.
See a model-free reinforcement learning AI figure out how to walk from trial and error. The programmer also introduces new Policies and Rewards as the AI improves.
Bridging Theory and Practice
In recent years, AI, specifically RL, has received the spotlight as a promising solution for enhancing energy efficiency, especially in HVAC systems which are crucial for maintaining optimal performance at data centers.
Data centers are the lifeblood of our digital age. They require intricate coordination between mechanical, electrical, and control systems to maintain the perfect operating environment for critical IT infrastructure. Thus, human operators, with their years of experience, are crucial to such a setup.
Imagine an HVAC operator who oversees a data center’s environment. The operator is surrounded by monitors displaying a plethora of data—from current hot and cold aisle temperatures to the operational status of chillers and the supply air temperature. Their role is pivotal, blending experience and nuanced judgment to keep the data center running smoothly.
This scenario highlights how essential the skills of an experienced operator are. It also serves as a perfect analogy for the potential application of RL in data centers, not to replace an operator but to enhance performance that is both sustainable and cost-effective.
In an RL framework, the HVAC operator’s role is mirrored by an AI agent, with the data center acting as the environment. This agent, leveraging RL algorithms, continually interprets sensor data to make decisions that optimize the HVAC system's performance—much like the operator adjusting setpoints based on the data reviewed.
The agent strives for energy efficiency and system reliability, learning through trial and error to discover the most efficient strategies for maintaining optimal conditions. This iterative process exemplifies RL's distinctive approach of optimizing performance through direct, ongoing interaction with the environment.
Ultimately, DRL’s application will make data centers more energy-efficient and sustainable, potentially enhancing operational efficiency in essential infrastructure.
Deep Reinforcement Learning (DRL) and Its Advancements
DRL combines the strength of deep learning (i.e. deep neural networks) with a reinforcement learning architecture, allowing agents to process and learn from unstructured input data as well as from trial and error in the environment. This breakthrough led to significant advancements. From mastering the ancient game of Go to excelling at modern video games like StarCraft, DRL has been at the forefront, pushing the boundaries of what machines can learn and achieve.
Its capabilities to handle high-dimensional, sensory input make DRL the most suitable form of AI for real-world applications, like autonomous driving, industrial control systems, illness diagnosis, and complex game playing. In real world applications, there is little to no tolerance for trial and error, so any AI agent must be trained on good historical data before it is allowed to make decisions like driving, diagnosing illness or operating a mission critical facility. RL alone is not enough for mission critical applications.
Challenges and Future of Reinforcement Learning
RL has a powerful framework for teaching machines how to make decisions, but there are challenges it needs to navigate. The most common one seen is the exploration and exploitation trade-off. This is where RL agents must decide between exploring new actions to discover better rewards and exploiting familiar actions for immediate rewards.
Too much exploration can lead to unnecessary risks, but too much exploitation can also lead to missing out on optimal strategies. There must be balance. Of course, this all depends on the context.
When AI was first introduced in the United States in the 1950s-1960s, the idea was to find a way to maximize reward. Shortly after, the Soviets looked at using AI to minimize cost. Minimizing can be looked at as saving time and money while maximizing could be playing longer and accumulating more wealth. This is all intuition-based and depends on the human creator’s input that defines the reward and cost function.
The benefit of RL is that it can consider multiple steps into the future, beyond what most humans can do. So, how do you BEST operate this?
Imagine you’re a mouse in the maze. You have a safe zone, called “home” and an unexplored area surrounds you. All you know about this unexplored area is that a cat lurks about and there is more cheese.
Your objective is to get as much cheese as possible. So do you stay put in the neighborhood and play it safe where there is some cheese? Or do you venture into the unknown where there may be much more cheese and risk meeting the cat for that higher reward?
Also, why do you need to explore, especially when you don’t know the rules of the game? This isn’t like a game of chess where you know the rules already. You don’t know anything outside your home and can’t start planning until you explore (unlike chess) because sometimes you don’t know all the data until you start exploring.
Now, you could focus on getting the cheese around you right now. It’s sustainable short-term. A long-term victory, however, requires you to explore and is optimized when at the right time to avoid the cat. You’ll have to seek balance between short-term reward-seeking and long-term value.
So how does this translate to giving a machine the freedom it needs to decide whether to explore or exploit? This is where humans program comfortable risk-avoiding vs reward-seeking in. AI agents can be designed to allow for up to x% of comfortable risk for any given constraint. There may be more rewards the closer an AI explores to that risk level but going over it could be considered unwise and catastrophic. This means the AI will spend some of it’s time exploiting the best strategies it knows and some of it’s time exploring for better ones, as long as it avoids meeting that risk maximum. Human operators are the architects that weigh out the risk for minimum and maximum outcomes.
Future Directions and Trends in Reinforcement Learning
RL is rapidly evolving, with future advancements expected to revolutionize its applications. We can expect the development of more sophisticated agents that adapt more quickly to changing environments and handle more complex decision-making scenarios.
Moreover, RL's ability to optimize processes in real-time will profoundly impact sustainability and efficiency across various industries. Future trends may see RL algorithms further reducing waste, energy use, and carbon emissions in manufacturing, logistics, and energy production.
Future advancements are expected to focus on developing scalable and efficient agents capable of learning in highly complex, dynamic environments. This includes improvements in parallel processing, real-time learning capabilities, and the integration of RL with other forms of AI to create more comprehensive learning systems. These advancements will enable RL applications to scale up and become more prevalent in solving real-world problems. It can offer solutions to complex problems, open frontiers for innovation and growth, and help us reconsider our currently held beliefs and biases.
Another Excellent Resource on RL: Spinning up RL in Open AI

AI Readiness Checklist: Operational Data Collection & Storage Best Practices
Download our checklist to improve your facility’s data habits. Whether you are preparing for an AI solution or not, these will help increase the value of your data collection strategies.
Featured Expert
Learn more about one of our subject matter experts interviewed for this post

Veda Panneershelvam
Co-Founder, CTO
Veda is one of our 3 Co-founders and serves as Phaidra's Chief Technology Officer. In this capacity, he sets the technical and research direction for Phaidra, providing leadership on the AI-related tactical execution of customer deployments. He also leads teams responsible for Software Engineering and Research. Prior to Phaidra, Veda was at DeepMind working on a number of significant projects, most notably: Autonomous Self Driving technology, AlphaGo, Bootstrapping AlphaFold efforts and Google's Data Center Cooling Optimization. Prior to DeepMind, he worked as a Software Engineer specializing in distributed computing at Keane, Sentenial and Imtech.
Share
Recent Posts

AI | March 16, 2026
Phaidra, in collaboration with industry leaders NVIDIA and CoreWeave, announced a groundbreaking methodology to drastically improve the thermal stability of liquid-cooled AI data centers.

Product | March 04, 2026
Phaidra Prism is an AI assistant designed by data center experts for data center operators and technicians.

AI | January 07, 2026
An AI factory operates more like a formula 1 race car, not a typical data center. Find out how Phaidra's AI agents deliver real-time thermal control for synchronized GPU workloads at gigawatt scale while working with a broader partner ecosystem.
Subscribe to our blog
Stay connected with our insightful systems control and AI content.
You can unsubscribe at any time. For more details, review our Privacy Policy page.
